
Have you ever wanted to optimize Magento’s performance, but did not know where to start? Magento has a lot of components. It is possible to improve each of them, but which component improvement is really worth our time? I think that the category-product relations indexation definitely deserves our attention.
Indexation has improved significantly since the launch of Magento Enterprise 1.13. In older Magento versions, there was no such thing as ‘partial indexation’. A reindex implied the same things as a full reindex, namely every product would have been indexed again. In order to correct this behavior and improve the performance, a pseudo-Materialized View pattern was implemented and released. I am using the ‘pseudo’ prefix because MySQL barely supports non-Materialized Views and Magento implemented a sort of Materialized View.
What is the Materialized View?
As we all probably know, a design pattern offers a framework for resolving general problems. In this case, the format and tables used to store the data are the issues. Since Magento uses the EAV design pattern, a lot of joins are needed in order to retrieve certain needed data. So, the Materialized View pattern will generate a view. The view materializes the data in a format suited to the required results set.
In our case, we have the ‘catalog_category_product_index’ table as a materialized view that will store data regarding the category-product relations. This table will aggregate data from other tables. This means that it is possible to perform CRUD operations more easily by at any time deleting all of the data from this table. For this table, we have the following columns:
- category_id, product_id, and position, whose values are taken from the catalog_category_product table.
- is_parent, this is the category is_anchor attribute, whose value can be found in catalog_category_entity_int table.
- store_id, although the categories are not per store (only the root category is linked to zero or more stores), the products are. And Magento needs to keep track of this for multistore shops.
- visibility, this is the product visibility attribute, whose value can be found in catalog_product_entity_int.
Anchor categories
I previously mentioned the is_anchor category attribute. So what does it do? Basically, it is a ‘Yes/No’ flag, which answers the question ‘Should this category’s frontend page include a layered navigation block?’.
In practice, this attribute is useful when, for example, we would add products only to child or leaf categories. We would set the top categories as anchor. Then, when accessing any of the top categories, we would see the products assigned to any of the child categories.
Magento’s indexation
How does the Magento Enterprise 1.13 indexation work?
I think the best approach to understanding this process is to analyze the flow. And then, to see what happens step by step by staying near the category-product index.
Let’s suppose that we’re planning to unassign product A from category B. In order to do this, we need to go to Admin -> Catalog -> Categories -> Manage Categories, click on any existing category. Next, we click on the ‘Category Products’ tab. We uncheck the checkbox from the product A’s row on the displayed grid. Upon clicking the ‘Save Category’ button, the row containing their IDs and the product position on that category will be deleted from the ‘catalog_category_product’ table. Nothing fancy so far. But what about the indexed value of this relation that is found in the ‘catalog_category_product_index’ table?
Enterprise_Index
Starting from Magento Enterprise 1.13, we have a new module, called Enterprise_Index, which manages the index execution queue. Basically, this queue will handle the partial indexation and in our case, it will clear the garbage data, i.e. data from the ‘catalog_category_product_index’ table which is no longer valid due to updating products or categories entities. In the ‘sql’ folder of this module, we can find a script named ‘sql/enterprise_index_setup/install-1.13.0.0.php’, which includes the addition of multiple triggers to certain tables for better database access during the reindex. Another important part is the changelog tables, in which Magento will store entity IDs in order to know which entities need to be partially reindexed.
In a day-to-day vocabulary, when a relation is deleted from the ‘catalog_category_product’ table, a trigger installed on this table will insert a row into ‘catalog_category_product_index_cl’ having the new version of the index (an incremental number based on which Magento will know what data needs to be updated i.e. partially reindexed) and the ID of the changed entity. Next, Magento’s cron or, even, a Linux cron will listen for new entries in the changelog tables and update only changed data.
Magento’s relation indexation
If you have a shop with multiple stores, hundreds of categories (especially anchor ones) and tens or even hundreds of thousands of products, you might consider improving the catalog category product indexation process. In this case, the full indexation might take more than a couple of hours and the partial indexation will be proportional. It’s true that Magento’s indexation took a big step forward, but there is no perfect code. Any block of code can be improved and that’s what we’re gonna do next.
First of all, let’s set a context in order to know the amount of data with which the category product indexation will work. We will work on a Magento installation that has:
- 1 store
- 838 categories
- 809 anchor
- 29 non-anchor
- 82000 simple and grouped products (we don’t really care about the proportion)
- 470000 rows in catalog_category_product_index.
Regarding the hardware part, I am using a Vagrant virtual machine under a ‘Linux Mint 18 Sarah’ with the following specifications:
- 3 Intel Core i5-3330 CPUs @3.00GHz
- 4GB RAM.
Basically, there are three smaller parts in the catalog category product indexation process, as we can see in the following method, Enterprise_Catalog_Model_Index_Action_Catalog_Category_Product_Refresh::_reindex():
foreach ($this->_app->getStores() as $store) { /** @var $store Mage_Core_Model_Store */ $rootCatIds[] = $store->getRootCategoryId(); if ($this->_getPathFromCategoryId($store->getRootCategoryId())) { $this->_reindexNonAnchorCategories($store); $this->_reindexAnchorCategories($store); $this->_reindexRootCategory($store); }}
Before the improvement, the performance obtained for these three indexations parts are:
- Non-anchor categories – 48s
- Anchor categories – 8m29s
- Root category – 18s.
Understanding the logic
As we can see, the anchor categories indexation part takes the longest. Before starting the actual improvement, it’s essential to understand the logic. Otherwise, how can we improve it? Let’s see what
The Enterprise_Catalog_Model_Index_Action_Catalog_Category_Product_Refresh::_reindexAnchorCategories method
Let’s see what this method does:
/** * Reindex products of anchor categories * * @param Mage_Core_Model_Store $store */protected function _reindexAnchorCategories(Mage_Core_Model_Store $store){ $selects = $this->_prepareSelectsByRange($this->_getAnchorCategoriesSelect($store), 'entity_id'); foreach ($selects as $select) { $this->_connection->query( $this->_connection->insertFromSelect( $select, $this->_getMainTmpTable(), array('category_id', 'product_id', 'position', 'is_parent', 'store_id', 'visibility'), Varien_Db_Adapter_Interface::INSERT_IGNORE ) ); }}The logic here is pretty simple. Magento will construct a select statement, which will return the rows that will be inserted, in smaller chunks, into ‘catalog_category_product_index’ table. As we can see, this action is performed without manipulating data from PHP. So, it’s a MySQL performance problem. This select statement is actually split into multiple selects in order to not add unnecessary load to the database. Here is the original select statement used, before splitting.
This is what we need to improve:
SELECT cc.entity_id AS category_id, ccp.product_id, ccp.position + 10000 AS position, 0 AS is_parent, 1 AS store_id, IFNULL(cpvs.value, cpvd.value) AS visibilityFROM catalog_category_entity AS ccINNER JOIN catalog_category_entity AS cc2 ON cc2.path LIKE CONCAT(cc.path, '/%') AND cc.entity_id NOT IN ($rootCategoryId)INNER JOIN catalog_category_product AS ccp ON ccp.category_id = cc2.entity_idINNER JOIN catalog_product_website AS cpw ON cpw.product_id = ccp.product_id INNER JOIN catalog_product_entity_int AS cpsd ON cpsd.entity_id = ccp.product_id AND cpsd.store_id = 0 AND cpsd.attribute_id = $statusAttributeIdLEFT JOIN catalog_product_entity_int AS cpss ON cpss.entity_id = ccp.product_id AND cpss.attribute_id = cpsd.attribute_id AND cpss.store_id = 1INNER JOIN catalog_product_entity_int AS cpvd ON cpvd.entity_id = ccp.product_id AND cpvd.store_id = 0 AND cpvd.attribute_id = $visibilityAttributeIdLEFT JOIN catalog_product_entity_int AS cpvs ON cpvs.entity_id = ccp.product_id AND cpvs.attribute_id = cpvd.attribute_id AND cpvs.store_id = 1INNER JOIN catalog_category_entity_int AS ccad ON ccad.entity_id = cc.entity_id AND ccad.store_id = 0 AND ccad.attribute_id = $isAnchorAttributeIdLEFT JOIN catalog_category_entity_int AS ccas ON ccas.entity_id = cc.entity_id AND ccas.attribute_id = ccad.attribute_id AND ccas.store_id = 1WHERE (cpw.website_id = 1) AND (IFNULL(cpss.value, cpsd.value) = 1) AND (IFNULL(cpvs.value, cpvd.value) IN ($visibilityIDs)) AND (IFNULL(ccas.value, ccad.value) = 1) AND (cc.entity_id >= '1')At first glance, we can see that our main table is `catalog_category_entity` and our first join is built… on the same table… But why is that? Because Magento stores the hierarchy of a category as a category_id path enumeration (i.e. 1/2/3). By building the self join, we want to get every parent-child categories combinations, where the parent category is anchor. Due to this join, we will add every product assigned on the child category to the parent category from this relation. For example, if we have four anchor categories, one under the other, the leaf category will have the path as ‘1/2/3/4’. When making the self join, then we would get 6 rows returned so that we can make sure that every category will have assigned the products from any of its child.
The next step
is to get every assigned product from the child category that we self joined and filter them by store, status, and visibility. This may sound pretty simple, but there are a lot of joins that we need to make, and let’s not forget that improvement is our goal.
Luckily, Magento will help us here. If we look at the joins that are made to filter the products by status by taking the store and the default attribute values, we can see that an INNER and a LEFT join are made. Why are different joins made? When retrieving default values, it’s important to check that on the both sides we have values (i.e. Inner Join), while the store values may be missing (i.e. Left Join) and after that, just retrieve the value by using the IFNULL MySQL function (e.g. IFNULL(t2.value, t1.value)). In this way, we will retrieve the store value of the attribute and if there is no store value, then the select will fallback to the default value. Keep in mind that there may be some attributes which may have null store values on purpose and this logic would not be appropriate there.
Improving the relations indexation
Now that we understand the logic of the anchor categories, we can start improving this nasty select statement. I’ll leave the joy of writing the improvement code to you and I will only explain the new logic I implemented.
First of all, we need some data caching – more precisely, we need to cache every anchor category ID with their parent anchor categories IDs (and the category itself) in a class property in order to later know if and on which categories we shall index the products.
Now, let’s create the rows
which we’ll insert into the catalog_category_product_index table.
In order to do so, we need the product IDs with which we will work. If we’re full reindexing, then it’s safe to take every enabled and visible product ID.
But what about the partial reindexing? If we’re modifying two or three products, then we sure won’t reindex every product, right? This is simple to achieve because Enterprise_Catalog_Model_Index_Action_Catalog_Category_Product_Refresh_Changelog class will have the product IDs which need to be reindexed in the protected _limitationByProducts property when modifying one or more product entities.
Let’s not forget that we also need to reindex products when updating the category on which these products are assigned. And for this case, we have the protected _limitationByCategories property in the Enterprise_Catalog_Model_Index_Action_Catalog_Category_Product_Category_Refresh_Changelog class. This case requires an extra step because we would get the category IDs and we need to get their product IDs. Now, we have the product IDs, but we still need the product’s visibility and the categories to which the product is assigned, and their positions.
The next step
is to get the category IDs on which the previously retrieved products need to be indexed due to the is_anchor attribute. This is pretty simple because we have the category IDs on which the product is assigned. So, we can check every parent category ID if it was previously cached (remember that we cached only anchor categories?). If it’s not cached, then continue, otherwise create a row (i.e. array) with the following structure:
- category_id – represents the anchor parent category ID of a category on which the product is assigned.
- product_id – the product ID with which we’re currently working
- position
- is_parent – will always be 0 because it answers the question “Is this product assigned to this category?”
- store_id – store ID on which we’re working
- visibility – previously retrieved visibility attribute ID.
If anybody asks you “Do I have to know math to program?”, then the position computing is your answer. It took me a while to figure this out. But the product position on an anchor category can be defined as ‘10000 + the product position on the first child category’. For example, if we have two categories A and B. Product X is assigned only to category B with position 42, and category A is anchor. The indexation of product X on category A will have the position 10042. If we had an intermediate category between A and B, then the indexation for both categories, A and B, will have the position 10042.
Conclusion
So what are the results of all this blood, sweat, and MySQL? Let’s remember that the execution time for the old _reindexAnchorCategories method was 8 minutes and 29 seconds. And now, after all these changes, the method takes 22 seconds. The following graph may help us visualize the impact of our improvement:
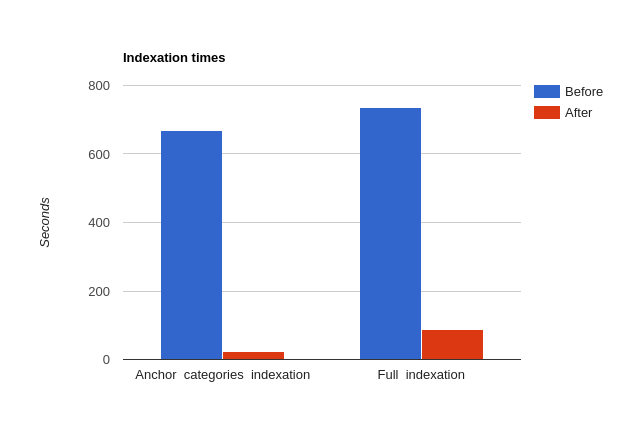
So we have a time improvement of 3040% for anchor categories and 835% for the ‘catalog_category_product’ index, which I consider to be pretty significant. By now you should be thinking about new features, which will make use of the resources this improvement will free up for you… but before this – do you think this improvement is worth it?
By Andrei Bodea
This article was first published here here.


