
So, you want to build an AI chatbot. Maybe it was my previous article on chatbot use-cases that led you here, or you already had the idea in your head and just need a few tips regarding how you can do it. Well, you have come to the right place.
Before starting, just a quick note that this article is designed to help tech people (meaning people who are comfortable with coding) start an AI Chatbot Development project. I will assume you are comfortable with 1 programming language (Python or JavaScript), know what an API is, how to use one, and what an LLM is.
Mostly, I will be talking about 3 different ways to develop an AI Chatbot:
- using an API
- fine-tuning a model
- using RAG
If you are looking for a way to build a chatbot that uses AI but aren’t comfortable with coding, then take a look at my other article meant for non-developers. (coming soon)
Now let’s get down to business:
The “I want ChatGPT on my website” chatbot
This is the easiest option. You practically just want your client to be able to talk to ChatGPT directly from your website. Maybe you have a pirate-themed website and just want to offer the user the possibility of talking to a “real live pirate”. If you ignore the possibility of hallucinations (it might invent dates or historical events), then this is the perfect option. Easy to implement, low costs, large knowledge base.
Here is how you do it:
- You build the interface of the AI chatbot using HTML, CSS, JavaScript, React or any other framework of your choosing.
- Choose your LLM taking into consideration the capabilities and costs. Check them out on HuggingFace.
- Get an API key. (HuggingFace or OpenAI)
- Check the documentation and see how you will need to send the information to the API. For example, for ChatGPT you will need to format it somewhat like in the code below.
let conversationHistory = []; // store here all the user questions and the answers from GPT to have context of previous questions and answers // store as { role: "user", content: userMessage } for user message // store as { role: "assistant", content: gptMessage } for answers const systemMessage={ role:'system', content:'Answer me like a pirate' } // this will be the initial prompt. // it can be simple like in the example or very complex with multiple instructions const generateResponse = (chatElement) => { const API_URL = "https://api.openai.com/v1/chat/completions"; const messageElement = chatElement.querySelector("p"); // or however you decide to extract the text from the user input conversationHistory.push({ role: "user", content: userMessage }); // push user message to conversationHistory before making the request // Define the properties and message for the API request const requestOptions = { method: "POST", headers: { "Content-Type": "application/json", "Authorization": `Bearer ${YOUR_API_KEY}` }, body: JSON.stringify({ model: "gpt-3.5-turbo", messages: [systemMessage, ...conversationHistory], }) } // Send POST request to API, get response and set the response as paragraph text fetch(API_URL, requestOptions) .then(res => res.json()) .then(data => { messageElement.textContent = data.choices[0].message.content.trim(); // although it looks wierd .choices[0],message.content is where you will find the text answer to the request conversationHistory.push({ role: "assistant", content: messageElement.textContent }); // add the answer to the conversation history }).catch(() => { messageElement.classList.add("error"); messageElement.textContent = "Oops! Something went wrong. Please try again." }
There certainly are better ways to implement this. I just wanted to give you a quick glimpse of how to send and receive messages to and from the API in order to build your AI chatbot. Now just show the response to the user and you are done!
For a more detailed explanation of how to work with OpenAI API, check out the documentation.
The “Still ChatGPT but with more specific answers” chatbot
If you can’t get the ChatBot to behave the way you like through prompting, you might want to think about fine-tuning a model. Fine-tuning is using a pre-trained model and training it on a dataset specific to your task. You will obtain an AI chatbot with more specific answers to your use-case. However, it will cost you more time and money.
So, before fine-tuning, try to find other ways of solving the problem. Here are some strategies for getting better results with ChatGPT that you can try before fine-tuning. If prompt engineering or prompt chaining (breaking complex tasks into multiple prompts) doesn’t work, then the next step is fine-tuning.
Use-cases for fine-tuning an AI Chatbot can be:
- Setting the style and tone of the AI Chatbot (you want to make it sound like a sarcastic pirate but prompting just doesn’t give you the specific type of sarcasm that you want)
- Getting it to answer in a specific format (maybe you want to feed it text and the chatbot will answer only with bullet points containing specific information from that text like persons mentioned in the text, tasks mentioned, deadlines etc.)
- Getting the AI chatbot to follow complex prompts (this can be useful if you want to increase security, reduce hallucinations and jailbreak possibilities)
- Handling edge cases in specific ways (you can specify exactly how you want it to answer in certain situations)
- Performing tasks that are hard to articulate in a prompt
Depending on the LLM that you want to finetune, the process will vary. You can use TensorFlow with Keras, PyTorch or just Python. Here you can find a tutorial for fine-tuning on HuggingFace, and here is the documentation for OpenAI fine-tuning.
No matter what LLM you choose, you will need 1 thing to fine-tune your AI chatbot: a dataset.
- the dataset you will use will determine the way the model is fine-tuned and the manner in which your AI chatbot will answer questions.
- the dataset should be in the style of Question — Answer
- you should have at least 50–100 entries in the dataset in order for the model to be trained efficiently
- make sure you include all relevant questions that you think your customers might ask, all edge-cases that you want to be treated differently and all questions that might pose security risks.
- the model will learn from your dataset how to answer specific questions but also in general (style, tone) and will offer a better result than the normal model on specific queries from the user.
If you want to be extra specific, you can always include prompts when using the model in your AI chatbot, just like you do when you use the regular model. After fine-tuning, you will receive a model name which you can just insert in your API request like this
const systemMessage={ role:'system', content:'Answer me like a pirate' } // prompt it however you like // use prompt engineering techniques on top of fine-tuning for better results const requestOptions = { method: "POST", headers: { "Content-Type": "application/json", "Authorization": `Bearer ${YOUR_API_KEY}` }, body: JSON.stringify({ model: '${YOUR_MODEL_NAME}', messages: [systemMessage, ...conversationHistory], }) }
If you want to fine-tune an OpenAI model I also recommend using this Google Colab project that takes you step by step through everything you need to do and even creates the dataset for you.
The “ChatGPT but he knows my business” chatbot
The issue with normal models and even fine-tuned models (although you can add some business-specific information when fine-tuning) is that they run on a general knowledge base. This can be useful for the way you want your AI Chatbot to behave, or it can completely suck and make it useless.
For example, let’s think of the following scenario. You have an online store with hundreds of products and want to create an AI Chatbot for your customers. You won’t be able to put all of your information about your products in a prompt and would need thousands of entries in your dataset for fine-tuning. The solution is simple: “I give up! This is not for me.”
Well, you are wrong. There is a way to train a model specifically on your knowledgebase (that can be thousands of documents) and create an AI Chatbot specific to your business.
Retrieval-augmented generation (RAG) is an AI framework for improving the quality of LLM-generated responses by grounding the model on external sources of knowledge. The RAG Chatbot development is more difficult, but not so much that it is something you need to be scared of.
There are multiple ways of building a RAG Chatbot but the main steps are the same:
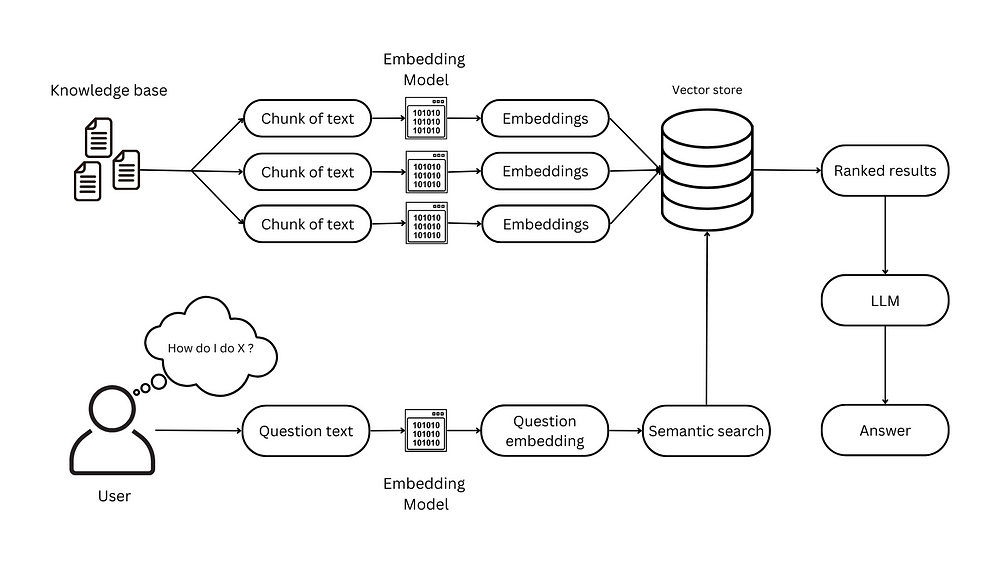
- The first step is to split all of the information into manageable chunks of text. You will send the most relevant chunks alongside the user question to the LLM. That is why you should use chunks around 1000-2000 tokens.
- Secondly, LLMs don’t really use text but embeddings which are a vectorised representation of information (text in our case). You will need to run all of the chunks through an Embedding Model in order to vectorise it. Take into consideration that the OpenAI embedding model is only ranked 13 (at the time of writing this) on the Embedding Leaderboard. Take a look at how they are ranked and choose the model that best suits you.
- You will then need to add the embeddings into a Vector Store of your choosing. Pinecone is the most popular but there are open source alternatives like Chroma or Qdrant that you can use. Take a look at this article to better understand what a Vector Store is and which you should use.
- The same needs to be done with the user’s question — run it through an embedding model
- You will then perform a semantic search on the Vector Store in order to receive the text chunks that contain the most relevant information, ranked by their relevance to your question.
- The question and the relevant chunks of text are then fed into the LLM of your choosing which can do its magic and create a nice answer to your question.
- The LLM can also be prompted in order to answer in specific ways and even fine-tuned if you wish.
You can do this in many different ways using Python or JavaScript. I recommend you use LangChain framework or EmbedChain as they make the process a lot easier. Here is an example using Python, LangChain and streamlit with FAISS as a vector database:
from dotenv import load_dotenv from PyPDF2 import PdfReader from langchain.text_splitter import CharacterTextSplitter from langchain.embeddings.openai import OpenAIEmbeddings from langchain.vectorstores import FAISS from langchain.chains.question_answering import load_qa_chain from langchain.llms import OpenAI import streamlit as st
def main(): load_dotenv() st.set_page_config(page_title="Chat with a PDF") st.header("Chat with a PDF 💬") # upload file that you want to "talk" to pdf = st.file_uploader("Upload your PDF file here", type="pdf") # extract the text and put it in a variable if pdf is not None: pdf_reader = PdfReader(pdf) text = "" for page in pdf_reader.pages: text += page.extract_text() # split into chunks with chunk size 1000 and overlap 200 char_text_splitter = CharacterTextSplitter(separator="\n", chunk_size=1000, chunk_overlap=200,length_function=len) text_chunks = char_text_splitter.split_text(text) # create embeddings and upload them into FAISS vector database embeddings = OpenAIEmbeddings() docsearch = FAISS.from_texts(text_chunks, embeddings) llm = OpenAI() chain = load_qa_chain(llm, chain_type="stuff") # take user input and make similarity search in vector database query = st.text_input("Type your question:") if query: docs = docsearch.similarity_search(query) response = chain.run(input_documents=docs, question=query) st.write(response) if __name__ == '__main__': main()
Benefits for each implementation
It’s time to put all 3 of the possible AI Chatbot implementations and see what the pros and cons are for each one.
Costs
- API call: the costs for this implementation are the lowest as you only pay for the number of tokens used in questions & answers.
- Fine-tune: the costs for fine-tuning are higher. You not only pay in order to fine-tune the model but, in the case of OpenAI, you pay around 4x more for tokens used in questions & answers for fine-tuned models.
- RAG: the cost here is also bigger than the simple API call and might also be bigger than fine-tuning. It will depend on the amount of information in your knowledge base. You will need to pay for embedding the information and also the number of tokens that you feed the LLM with when searching for an answer to the question.
Development difficulty:
- API call: very easy to implement. Beginner level.
- Fine-tune: easy to implement but might require a lot of work in order to create the dataset.
- RAG: medium-level difficulty, will need some experience with Python or LangChain framework.
Interaction with the user
- API call: will interact just like ChatGPT (or any other model) when prompted to answer in a specific way. It will offer mostly general information.
- Fine-tune: more custom interaction. Besides classical prompting, it can handle edge-cases better. It can be fine-tuned in order to be more secure and harder to jailbreak or hallucinate. It can also answer specific business questions if they are present in the dataset but will mostly offer general information. This will depend on how big and complex the dataset you fine-tune it with is.
- RAG: best for situations where you want precise answers with information from a custom knowledge base. This will offer the best user interaction if the user wants to find out detailed information about your business and not just general information.
_________________________________________________________________
So, this is it. These are the 3 techniques I would use for AI Chatbot development if I would like to get my hands dirty and write some code. There are no-code (or low code) alternatives that I will be presenting in a future article (coming soon). If you want some inspiration regarding use-cases for chatbots, then take a look at this article that is already published.
Have a nice day!


